If you are moving your data from Microsoft DataLake or BYOD to Microsoft Fabric, you will notice that some fields are missing in Fabric. This is a problem, especially if your are dealing with important tables and data entities like FinancialDimensionValue. In this blog post, I will show you how to add FinancialDimensionValue table from D365FO to Fabric.
Adding FinancialDimensionValue table from D365FO to Fabric
If you ever analyzed the SQL views for this data entity, you will notice it’s using many other views and tables to actually build the list of financial dimension values:
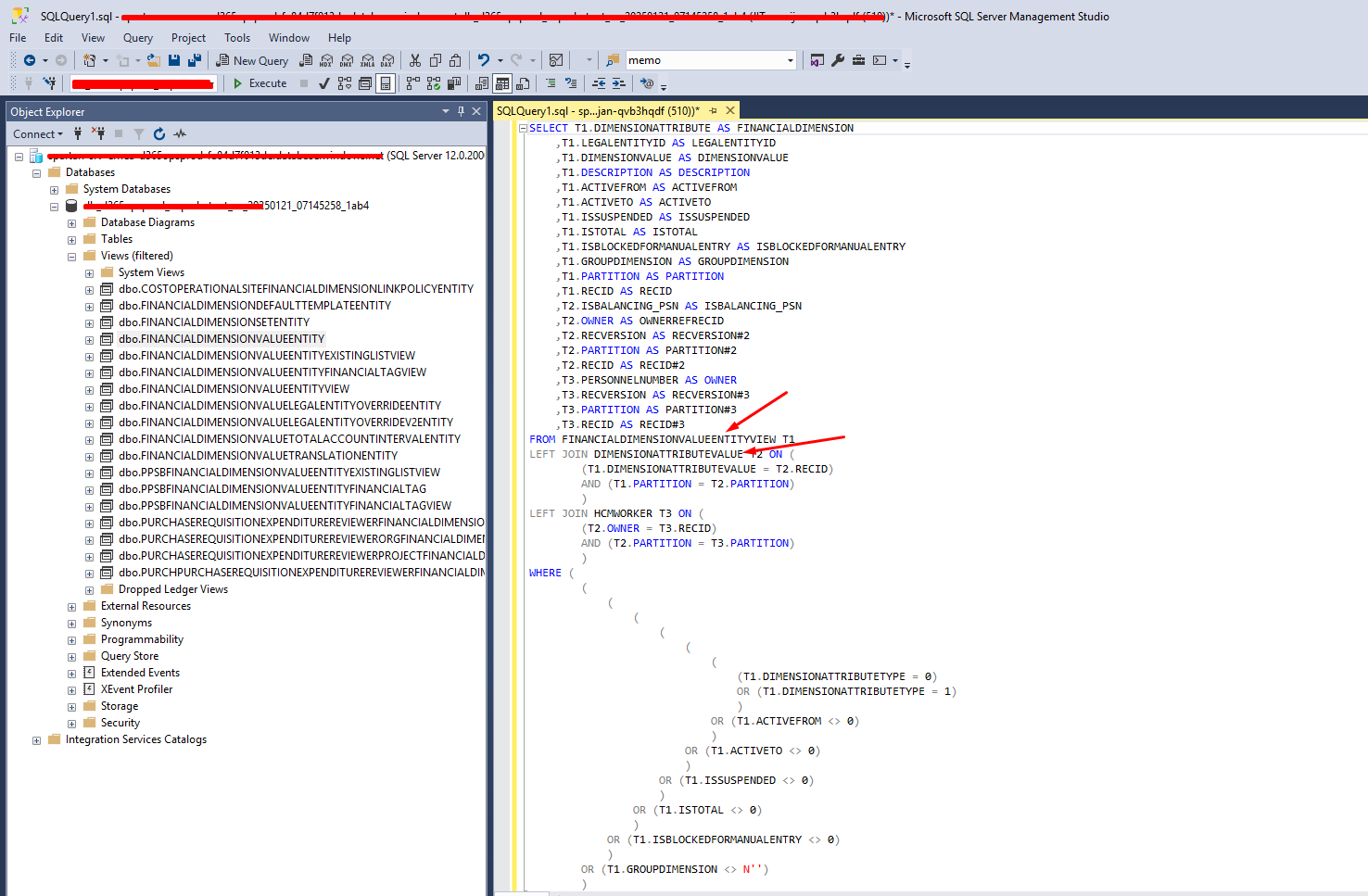
Note: When altering SQL views (to see how they work), you will notice that the code looks ugly:
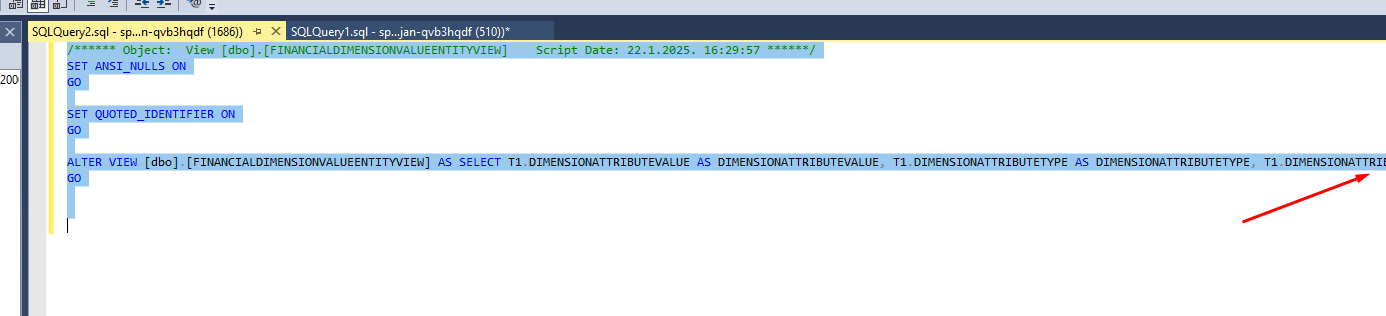
I used a free tool called BeautifyCode.net to make the code more readable like this:
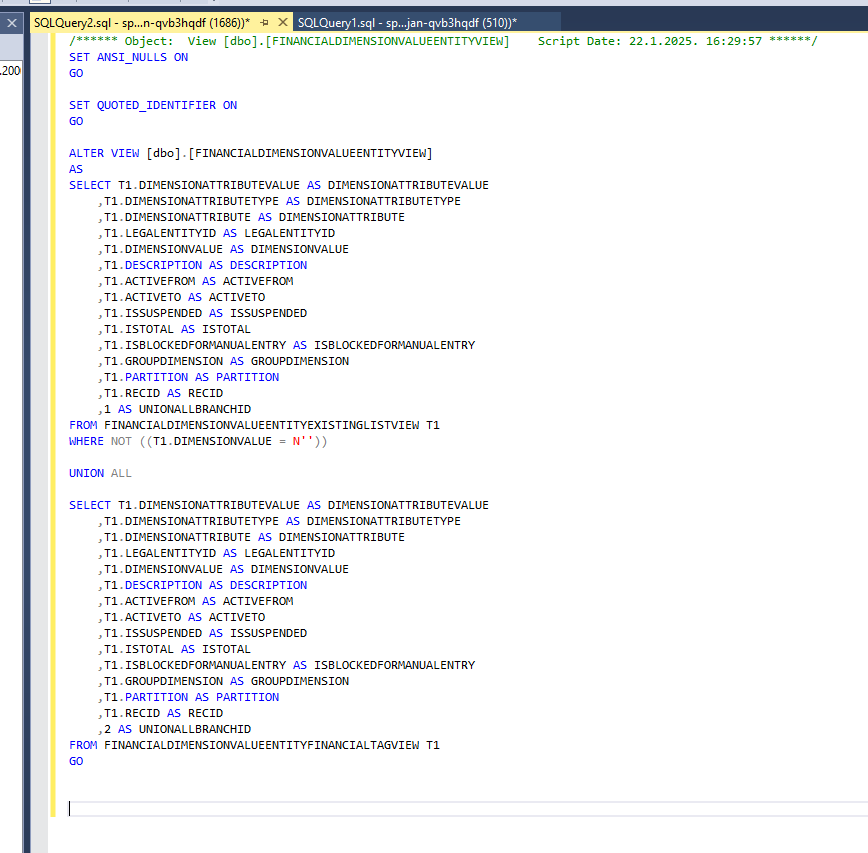
Here are some of the most common tables you will see in this whole logic of creating the Financial Dimension Value entity:
- OMOperatingUnit
- DimensionAttributeValue
- DimensionAttribute
- DirPartyTable
- DimensionFinancialTag
- DimensionAttributeDirCategory
At some point, you will notice that the view is using the field OMOperatingUnitType from the table DirPartyTable.
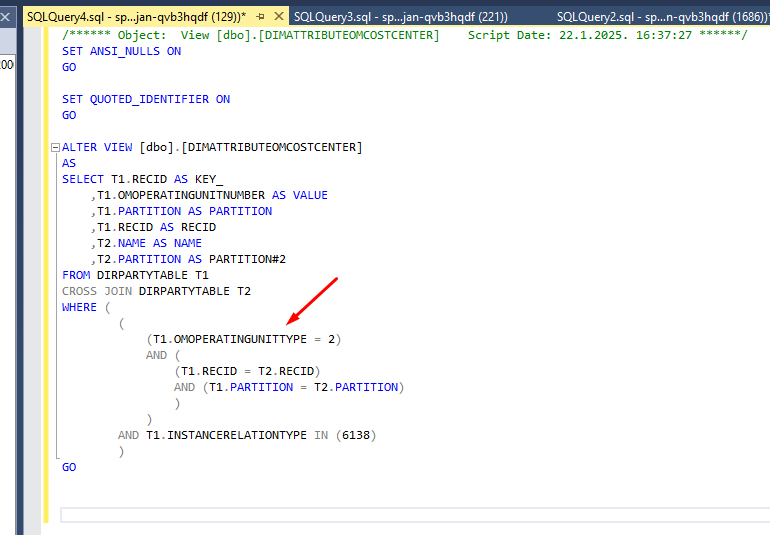
If you check this table on your D365 Sandbox SQL, you will see the field is there:
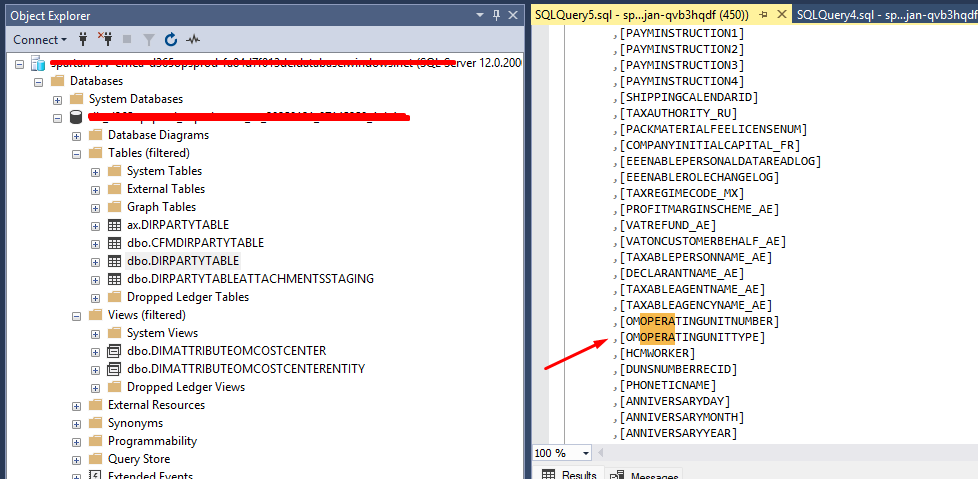
The problem is that the field doesn’t exist in OneLake. Actually, the table has much less fields:
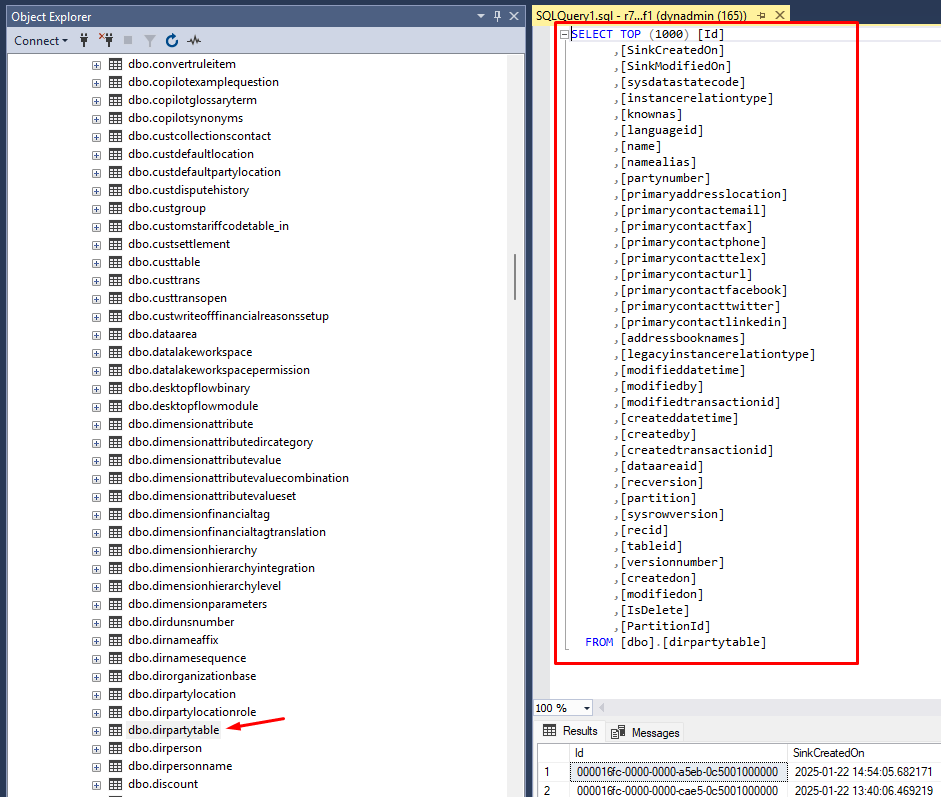
Now here comes the fun part! The only way I found to solve this problem is to somehow re-create the logic using the tables and fields that you already have in OneLake.
I needed the following columns in my Lakehouse:
- Dimension
- Dimension Value
- Description
So, I ended up with the following SQL query for my Department and Line Of Business dimensions:
select
da.name as dimension,
dav.displayvalue as dimensionvalue,
dp.name as description
from
omoperatingunit as om
inner join
dimensionattributevalue as dav
on om.recid = dav.entityinstance
inner join
dimensionattribute as da
on dav.dimensionattribute = da.recid
inner join
dirpartytable as dp
on om.recid = dp.recid and om.partition = dp.partition
where
om.omoperatingunittype in (2, 3) and da.viewname in ('DimAttributeOMValueStream','DimAttributeOMCostCenter')
order by da.name,dav.displayvalue
Note: I also hate hardcoding, but the hardcoded values were also hardcoded in SQL view on my D365FO sandbox.
The second SQL query was for all the other dimensions that I have:
select
t4.name as dimension,
t1.value as dimensionvalue,
t1.description as description
from dimensionfinancialtag t1
cross join dimensionattributedircategory t2
left join dimensionattributevalue t3 on (
(
(
(t2.dimensionattribute = t3.dimensionattribute)
and (t2.partition = t3.partition)
)
and (
(t1.recid = t3.entityinstance)
and (t1.partition = t3.partition)
)
)
and (t3.isdeleted = 0)
)
cross join dimensionattribute t4
where (
(
(t1.financialtagcategory = t2.dircategory)
and (t1.partition = t2.partition)
)
and (
(t2.dimensionattribute = t4.recid)
and (t2.partition = t4.partition)
)
)
ORDER BY dimensionattribute, dimensionvalue
When I converted this to PySpark, I ended up with the following code:
Import Required Source Tables
from pyspark.sql import functions as F
# Define the base path for tables in the Lakehouse
D356_landing_lakehouse_path = "abfss://yourlakehouseURL.Lakehouse/Tables/"
# Define table names
omoperatingunit_table = "omoperatingunit"
dimensionattributevalue_table = "dimensionattributevalue"
dimensionattribute_table = "dimensionattribute"
dirpartytable_table = "dirpartytable"
dimensionfinancialtag_table = "dimensionfinancialtag"
dimensionattributedircategory_table = "dimensionattributedircategory"
# Load the first dataset (Dept/LOB)
omoperatingunit = spark.read.format("delta").option("inferSchema", "true").option("header", "true").load(D356_landing_lakehouse_path + omoperatingunit_table)
dimensionattributevalue = spark.read.format("delta").option("inferSchema", "true").option("header", "true").load(D356_landing_lakehouse_path + dimensionattributevalue_table)
dimensionattribute = spark.read.format("delta").option("inferSchema", "true").option("header", "true").load(D356_landing_lakehouse_path + dimensionattribute_table)
dirpartytable = spark.read.format("delta").option("inferSchema", "true").option("header", "true").load(D356_landing_lakehouse_path + dirpartytable_table)
# Load the second dataset (Other dimensions)
dimensionfinancialtag = spark.read.format("delta").option("inferSchema", "true").option("header", "true").load(D356_landing_lakehouse_path + dimensionfinancialtag_table)
dimensionattributedircategory = spark.read.format("delta").option("inferSchema", "true").option("header", "true").load(D356_landing_lakehouse_path + dimensionattributedircategory_table)
Column Selection & Join Operations
# First query (Dept/LOB)
query1_df = (
omoperatingunit
.join(dimensionattributevalue, omoperatingunit["RECID"] == dimensionattributevalue["ENTITYINSTANCE"], "inner")
.join(dimensionattribute, dimensionattributevalue["DIMENSIONATTRIBUTE"] == dimensionattribute["RECID"], "inner")
.join(dirpartytable, (omoperatingunit["RECID"] == dirpartytable["RECID"]) & (omoperatingunit["PARTITION"] == dirpartytable["PARTITION"]), "inner")
.filter(
(omoperatingunit["OMOPERATINGUNITTYPE"].isin(2, 3)) &
(dimensionattribute["VIEWNAME"].isin("DimAttributeOMValueStream", "DimAttributeOMCostCenter"))
)
.select(
dimensionattribute["NAME"].alias("dimension"),
dimensionattributevalue["DISPLAYVALUE"].alias("dimensionvalue"),
dirpartytable["NAME"].alias("description")
)
)
# Second query logic (Other dimensions)
query2_df = (
dimensionfinancialtag
.crossJoin(dimensionattributedircategory)
.join(
dimensionattributevalue,
(dimensionattributedircategory["DIMENSIONATTRIBUTE"] == dimensionattributevalue["DIMENSIONATTRIBUTE"]) &
(dimensionattributedircategory["PARTITION"] == dimensionattributevalue["PARTITION"]) &
(dimensionfinancialtag["RECID"] == dimensionattributevalue["ENTITYINSTANCE"]) &
(dimensionfinancialtag["PARTITION"] == dimensionattributevalue["PARTITION"]) &
(dimensionattributevalue["ISDELETED"] == 0),
"left"
)
.crossJoin(dimensionattribute)
.filter(
(dimensionfinancialtag["FINANCIALTAGCATEGORY"] == dimensionattributedircategory["DIRCATEGORY"]) &
(dimensionfinancialtag["PARTITION"] == dimensionattributedircategory["PARTITION"]) &
(dimensionattributedircategory["DIMENSIONATTRIBUTE"] == dimensionattribute["RECID"]) &
(dimensionattributedircategory["PARTITION"] == dimensionattribute["PARTITION"])
)
.select(
dimensionattribute["NAME"].alias("dimension"),
dimensionfinancialtag["VALUE"].alias("dimensionvalue"),
dimensionfinancialtag["DESCRIPTION"].alias("description")
)
)
# Combine both DataFrames
result_df = query1_df.unionByName(query2_df)
# Show the combined results
result_df.show()
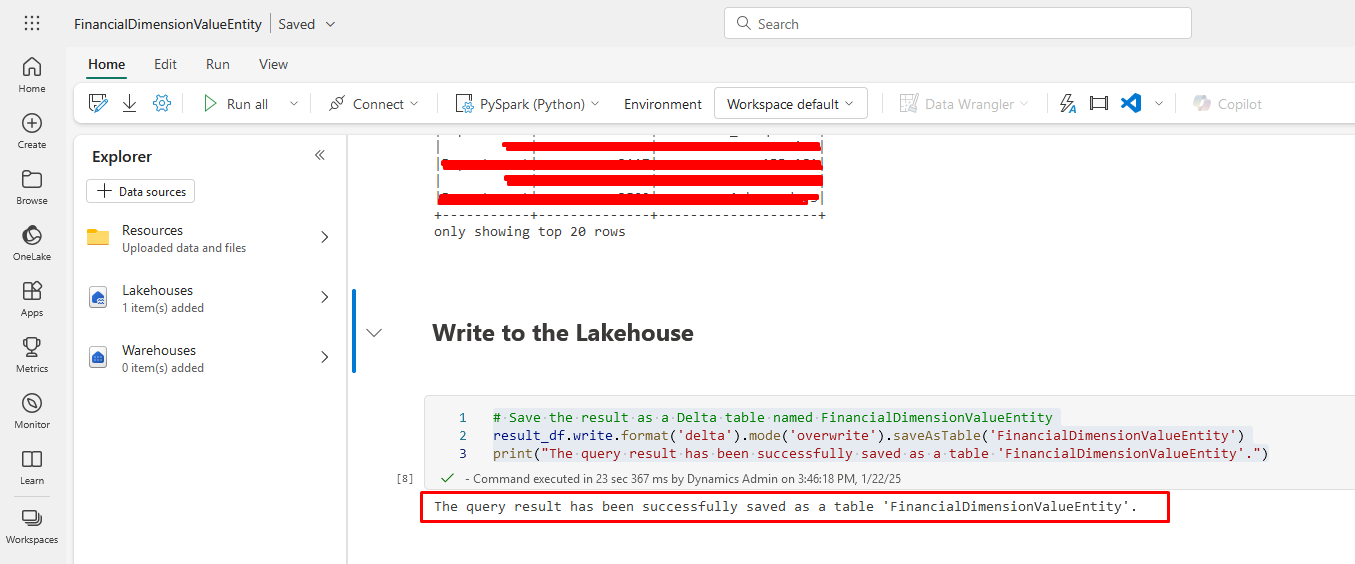
Write to the Lakehouse
# Save the result as a Delta table named FinancialDimensionValueEntity
result_df.write.format('delta').mode('overwrite').saveAsTable('FinancialDimensionValueEntity')
print("The query result has been successfully saved as a table 'FinancialDimensionValueEntity'.")
Once you run this Notebook, you will get the table with financial dimension values:
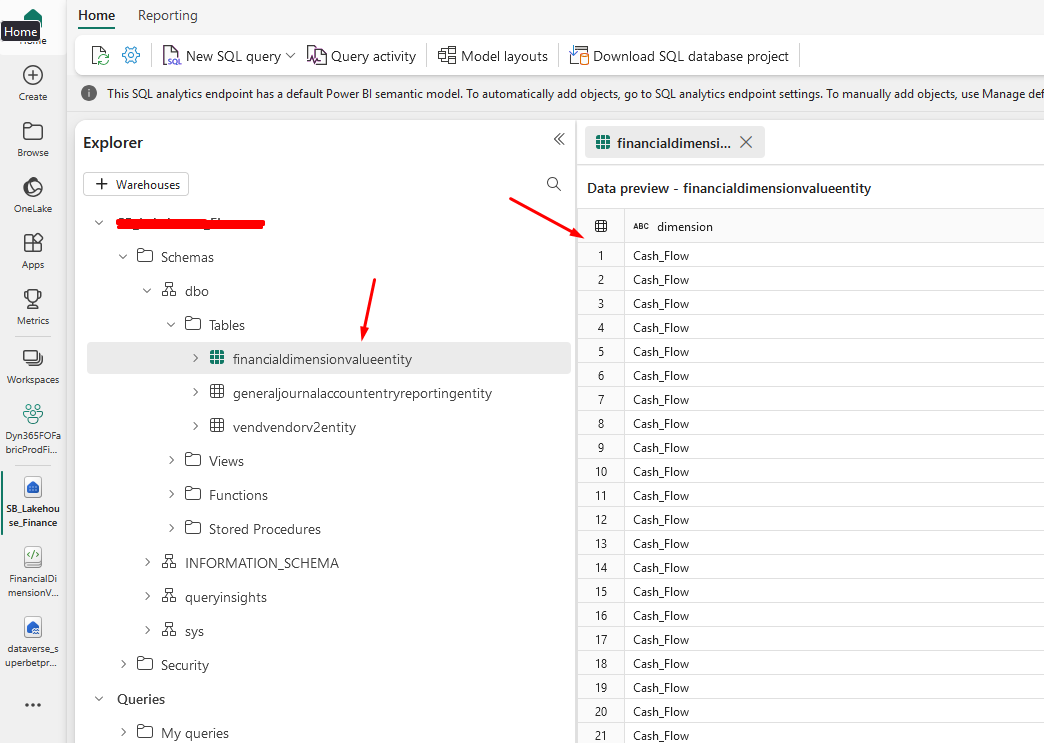
And you will see that the data is in your Lakehouse:
I hope this post will at least give you some idea on how to add FinancialDimensionValue table from D365FO to Fabric.
Make sure you check one of my previous blog posts on Microsoft Fabric and D365 F&O. If you want to learn more about the ERP itself, make sure you check out my blog post on How to Delete Financial Dimension Sets in D365FO.
If you want to learn more about Microsoft Fabric Notebooks, make sure you check out this link. There is also a great book on Amazon called Learn Microsoft Fabric: A practical guide to performing data analytics in the era of artificial intelligence that covers some interesting topics.